
这篇博客介绍了选用Xinference作为RAGFlow的模型推理框架的技术说明。
Xinference部署
在本地使用RAGFlow搭建知识库时,为了数据不泄露至互联网,需要先安装模型推理框架从而便捷的部署LLM、Embeding Model和Reranke Model等模型。由于Ollama对模型只支持LLM和Embeding Model部署。而Xinferce支持不仅各种模型,还支持各种模型格式。所以选用Xinference作为RAGFlow的模型推理框架。
Xinference安装
Xinference有两种安装方式:Docker和pip。本篇主要讲pip安装方式,如果想了解Xinerence的话建议去中文版文档地址:https://inference.readthedocs.io/zh-cn/latest/index.html。
使用conda创建虚拟环境
conda简介和使用在这里就不详细说明了,需要注意的是使用conda时,最好改一下conda源和pip源
# 创建环境
conda create --name xinfer python=3.12
# 进入环境
conda activate xinfer
安装Xinference
Xinference支持多种推理引擎,我目前只使用了Transformers和vLLM这两个引擎后端
1. Transformers引擎
pip install "xinference[transformers]"
2. vLLM引擎
pip install "xinference[vllm]"
# 一些模型可能需要用到FlashInfer
pip install flashinfer -i https://flashinfer.ai/whl/cu124/torch2.4
# 此处的镜像可以上aliyun
# https://mirrors.aliyun.com/pytorch-wheels/cu124/?userCode=okjhlpr5
方法 1:使用 wget
wget https://mirrors.aliyun.com/pytorch-wheels/cu128/flashinfer/flashinfer_python-0.2.5+cu128torch2.7-cp38-abi3-linux_x86_64.whl
方法 2:使用 curl
curl -O https://mirrors.aliyun.com/pytorch-wheels/cu128/flashinfer/flashinfer_python-0.2.5+cu128torch2.7-cp38-abi3-linux_x86_64.whl
下载完成后,确认文件已下载:
ls | grep flashinfer_python
安装 .whl 文件:
pip install flashinfer_python-0.2.5+cu128torch2.7-cp38-abi3-linux_x86_64.whl
确保当前 Python 环境与 .whl 文件的依赖(如 Python 3.8 和 CUDA 12.8)兼容。
# 对于不同的Cuda和torch版本可以查看https://docs.flashinfer.ai/installation.html 这个网页进行安装
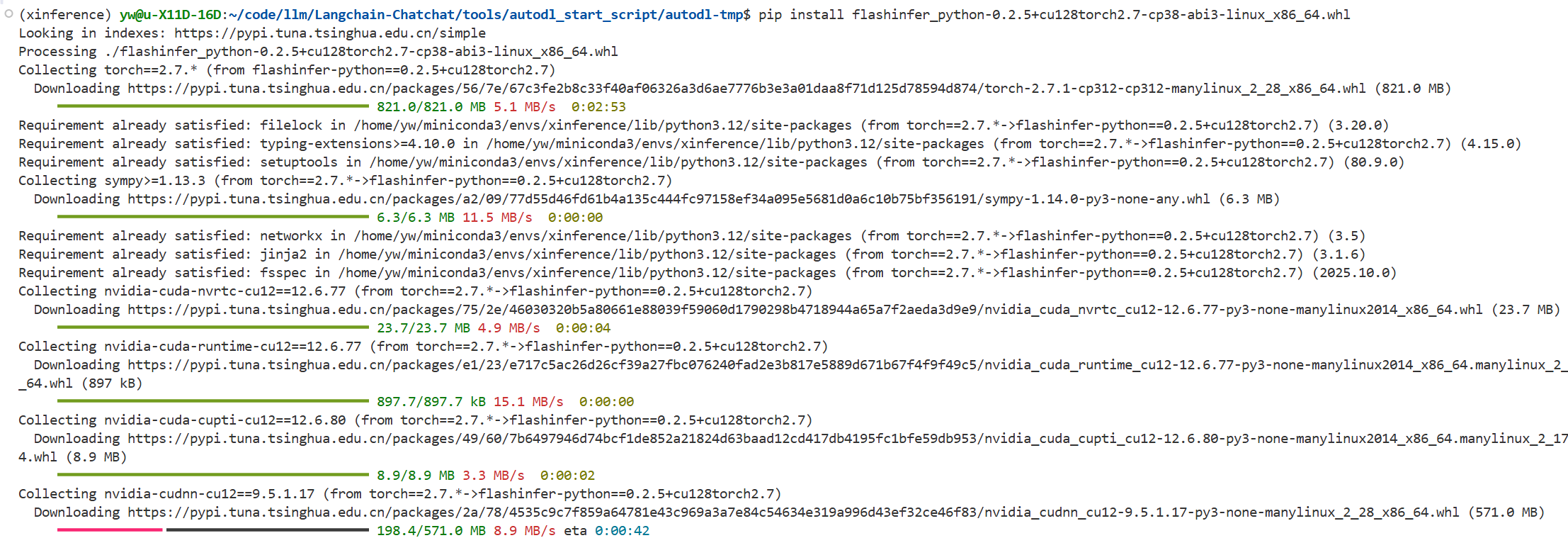
注:flashinfer的介绍 也可同时安装 Transformer和vLLM引擎
pip install "xinference[transformers, vllm]"
3. 安装所有引擎(可选)
pip install "xinference[all]"
注:我在其他教程上看到在 Xinference 安装过程中,有可能会安装 PyTorch 的其他版本(其依赖的vllm组件需要安装),从而导致 GPU 服务器无法正常使用,因此在安装完 Xinference 之后,可以执行以下命令看 PyTorch 是否正常:
python -c "import torch; print(torch.cuda.is_available())"
但实际上笔者没有试过,因为笔者是新创了一个conda虚拟环境安装,从来没有遇到过这个问题,所以笔者猜测是在已有的conda环境安装才会遇到这个问题。
部署模型
1. 设置环境变量(可选)
- 设置
XINFERENCE_HOME、 是Xinference用来存储信息或数据的(比如模型文件)。在Linux系统中一般位于/home/用户/.xinference目录下。可以通过配置环境变量修改。 -
打开
.bashrc sudo vim ~/.bashrc需要注意的,设置
XINFERENCE_HOME的终端和启动Xinference的终端必须是同一个终端窗口,笔者曾经在一个终端窗口设置环境变量,一个窗口启动。后来发现设置的环境变量并没有生效。 - 设置
HF_ENDPOINTXinference 模型下载默认是从Huggingface官方网站下载 。在国内因为网络原因,可以通过下面的环境变量设计为其它镜像网站:HF_ENDPOINT=https://hf-mirror.com/具体设置步骤与上述相同。 另外也可通过设置XINFERENCE_MODEL_SRC=modelscope,使其默认从modelscop下载。
#打开
nano ~/.bashrc
# 设置 Hugging Face 镜像源为 hf-mirror.com
export HF_ENDPOINT=https://hf-mirror.com
# 或者选择 设置模型下载源为 ModelScope
export XINFERENCE_MODEL_SRC=modelscope
# Xinference 配置:指定数据存储目录
export XINFERENCE_HOME=/home/pepper/data/xinference_data
# 激活
source ~/.bashrc
## 验证
echo $XINFERENCE_HOME
echo $HF_ENDPOINT
启动Xinference
xinference-local --host 0.0.0.0 --port 9997
Xinference 默认会在本地启动服务,因为这里配置了–host 0.0.0.0参数,使非本地客户端也可以通过机器的 IP 地址来访问 Xinference 服务。端口默认为 9997,可以使用–port配置其他端口。 启动成功后,可以通过http://IP:9997,访问WebGUI界面。
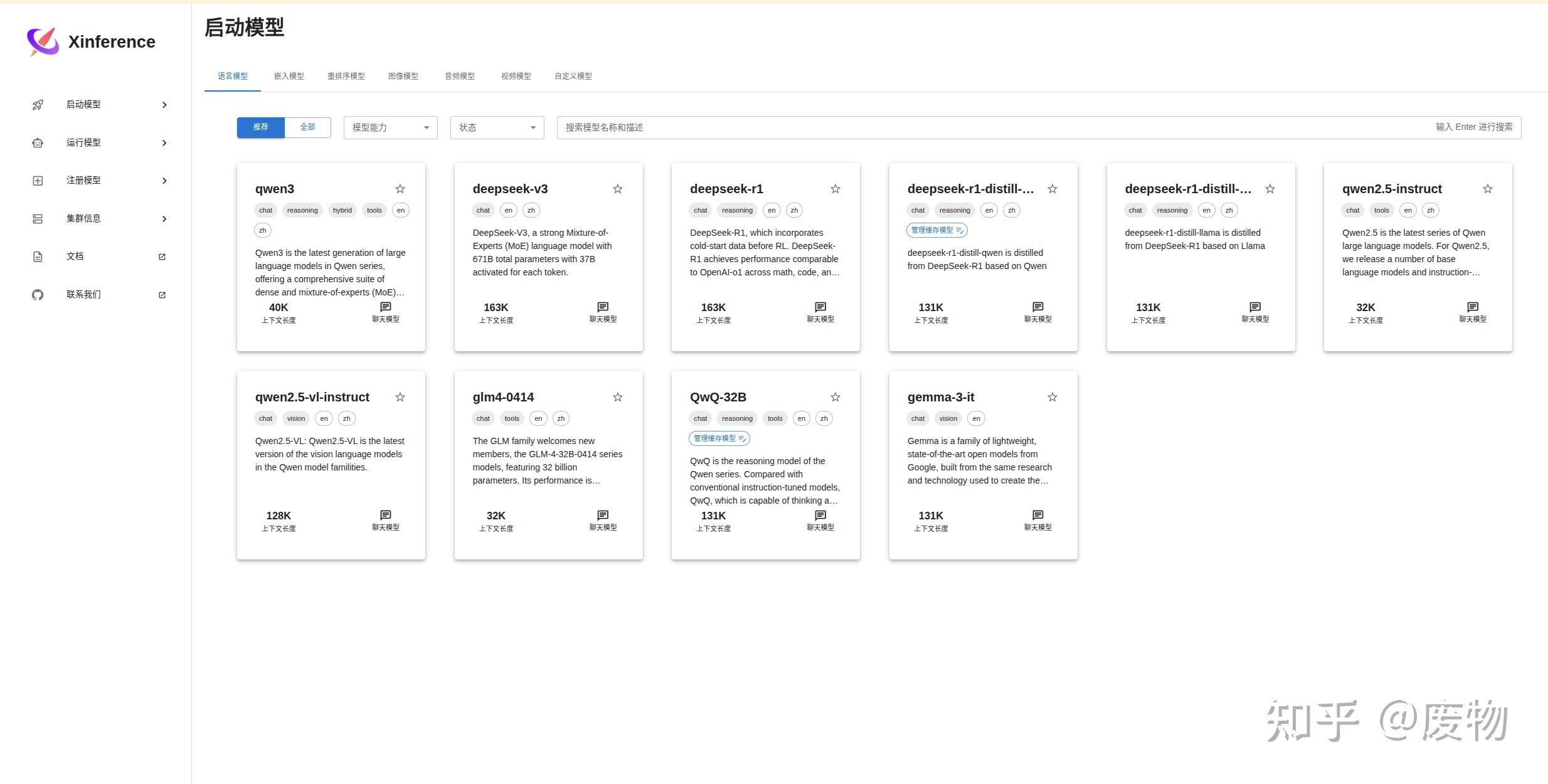
2. 使用Xinference部署模型
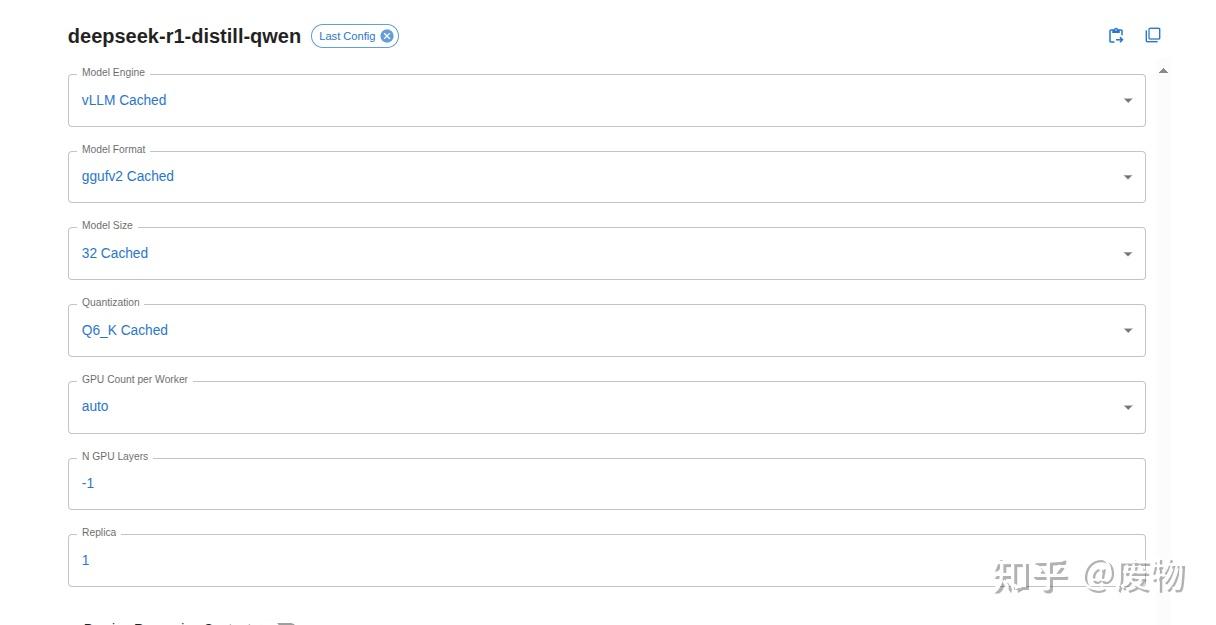
在Xinference上可以部署多种模型,比如大语言模型、嵌入模型等,甚至可以部署自定义模型。笔者将以部署DeepSeek-R1模型为例,阐述如何部署模型和部署过程中需要注意的地方。由于笔者使用的显卡显存为48G。所以选择DeepSeek-R1:32b量化后的6bit版本。其模型的基本配置如下:
我选择modelscope作为模型的下载源,其配置如下:
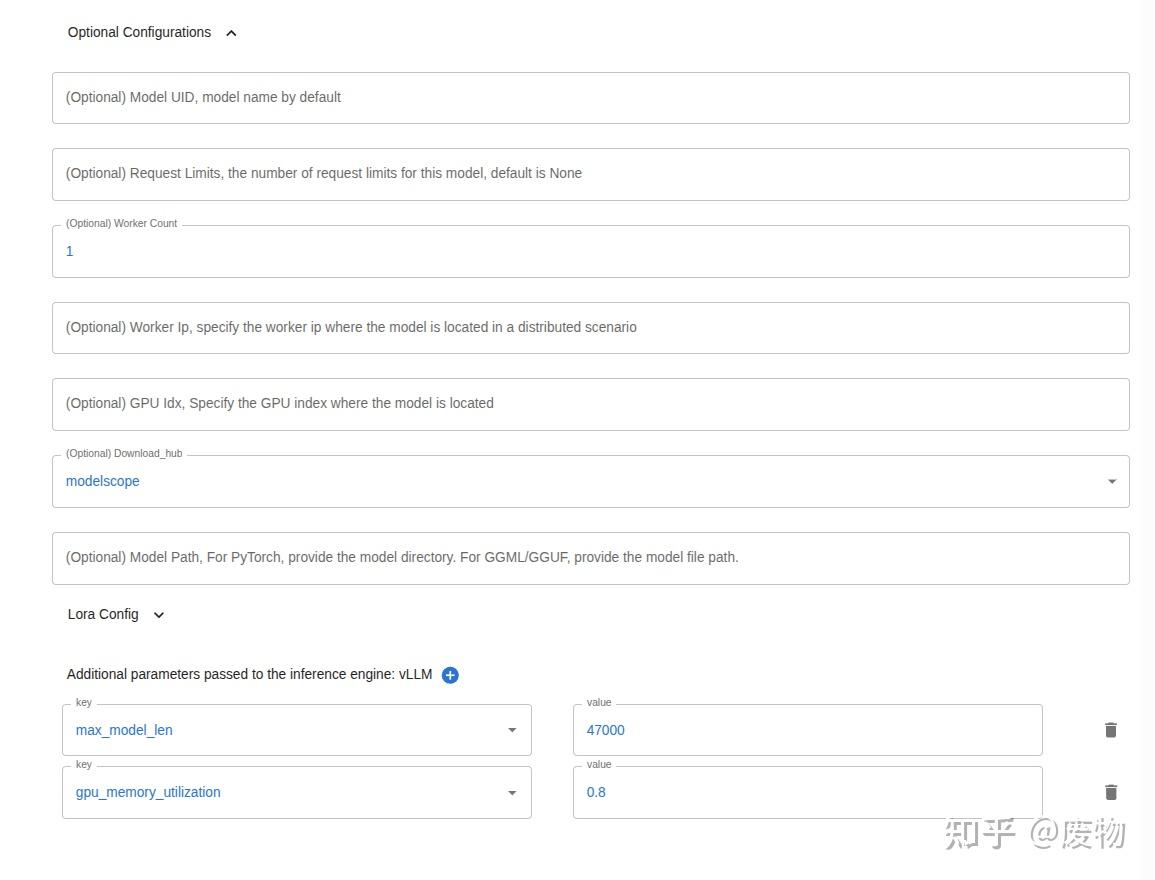
其中需要着重讲一下vLLM的配置参数gpu_memory_utilization和max_model_len.
gpu_memory_utilization:vLLM在部署模型过程中会为其预先分配显存,gpu_memory_utilization值越大,预先分配的显存就越大,一般默认值为0.9。比如 本机总显存为48G,gpu_memory_utilization=0.9,那么为模型预先分配显存的就是48G*0.9,预先分配显存越大,就有更多显存可用于 KV 缓存,推理速度也会越快。在显存足够的情况下,gpu_memory_utilization可以设置为0.95。这也是为什么部署一模一样的量化模型,使用vLLM要比使用Ollama部署占用的显存多的原因。
max_model_len:模型的最大生成长度,包含prompt长度和generated长度。这个值需要根据gpu_memory_utilization设置。经过测试笔者推测模型预先分配显存-模型部署本身需要的显存=模型的最大生成长度。笔者以部署DeepSeek32b-6bit量化版简单做了个实验,实验结果如下:
| gpu_memory_utilization | max_model_len | model size | 显存差 |
|---|---|---|---|
| 0.6(28.8G) | 8122 | 25.1G | 3.7G |
| 0.7(33.6G) | 27584 | 25.1G | 8.5G |
| 0.8(38.4G) | 47056 | 25.1G | 13.3G |
| 0.9(43.2G) | 66523 | 25.1G | 18.1G |
如果在部署过程中碰到”The model’s max seq len (131000) is larger than the maximum number of tokens that can be stored in KV cache (66512). Try increasing gpu_memory_utilization or decreasing max_model_len when initializing the engine.”这个报错,那么代表着自己设置的max_model_len=131000太大了,超过了当前显存可生成的KV cache(66512)。
所以有两个解决办法:1)将max_model_len设置小于当前显存生成的最大值就可以了。2)修改gpu_memory_utilization 使其模型占用的显存变大,从而使可以生成的KV cache变多。
报错记录
1.
2025-11-17 13:05:58.280 Uncaught app exception
Traceback (most recent call last):
File "/home/pepper/miniconda3/envs/chatchat/lib/python3.11/site-packages/streamlit/runtime/scriptrunner/script_runner.py", line 600, in _run_script
exec(code, module.__dict__)
File "/home/pepper/code/llm/Langchain-Chatchat/libs/chatchat-server/chatchat/webui.py", line 77, in <module>
dialogue_page(api=api, is_lite=is_lite)
File "/home/pepper/code/llm/Langchain-Chatchat/libs/chatchat-server/chatchat/webui_pages/dialogue/dialogue.py", line 418, in dialogue_page
upload_image=upload_image,
^^^^^^^^^^^^
UnboundLocalError: cannot access local variable 'use_mcp' where it is not associated with a value
3. 配置手动磁力下载模型
经典多线程工具推荐两个:IDM、Aria2。 IDM 适用于 Windows、aria2 适用于 Linux/Mac OS。
-
方法1 : 获取并提供 Hugging Face 令牌
步骤 1: 获取 Hugging Face 访问令牌 (Token)
- 访问令牌设置页面: 前往
https://huggingface.co/settings/tokens - 创建新令牌: 点击 “New token” (新建令牌)。
- 为令牌命名(例如 xinference-download)。
- 选择 “Role”(角色)为 Read(读取),这是下载模型所需的最低权限。
- 点击 “Generate a token”(生成令牌)。
- 复制令牌: 令牌生成后只会显示一次,请务必将其复制并妥善保管。
步骤 2: 使用令牌运行下载命令
- 由于你的脚本提示需要传递
--hf_username和--hf_token,你可以修改你的下载命令,将用户名和令牌作为参数传入。 格式:
./hfd.sh 模型ID \--hf\_username 你的用户名 \--hf\_token 你的令牌 \--exclude ...示例(请替换为你自己的信息):
./hfd.sh meta-llama/Llama-2-7b \--hf\_username 你的HuggingFace用户名 \--hf\_token 你复制的令牌 \--exc - 访问令牌设置页面: 前往
-
方法2 :使用
huggingface-cli login如果你的
./hfd.sh脚本底层是调用huggingface_hub库,那么你可以先在终端中执行登录命令,让系统记住你的凭证:登录: 在终端中运行以下命令:
huggingface-cli login输入令牌: 系统会提示你输入在步骤 1 中获取的 Hugging Face 令牌。
git config --global credential.helper store # 存储地方 cat /home/peper/.cache/huggingface/token重新运行下载: 登录成功后,再次运行你的原始下载命令:
# 可以手动限制下载的内容 ./hfd.sh meta-llama/Llama-2-7b --exclude \*.bin \*.msgpack onnx/